内容创作者如何被 AI 答案引用
关键词堆砌在生成式搜索里开始失灵,真正提高引用机会的是来源、数据、引言和清晰结构。KDD 2024 GEO 论文证明:小网站也可能靠内容质量,在 AI 答案中抢回可见度。
Topics
4摘要
关键词堆砌在生成式搜索里开始失灵,真正提高引用机会的是来源、数据、引言和清晰结构。KDD 2024 GEO 论文证明:小网站也可能靠内容质量,在 AI 答案中抢回可见度。
内容创作者如何被 AI 答案引用
原文:Pranjal Aggarwal、Vishvak Murahari、Tanmay Rajpurohit、Ashwin Kalyan、Karthik Narasimhan、Ameet Deshpande,《GEO: Generative Engine Optimization》,KDD 2024。arXiv:2311.09735
这篇论文想解决什么问题
过去三十年里,搜索引擎重塑了人类获取信息的方式,但它做的事情其实很”笨”:输入关键词,返回一串相关网页链接,剩下的阅读和判断工作全部留给用户。大语言模型出现后,情况变了。BingChat、Google 的 SGE、Perplexity.ai 这类产品不再只是”列链接”,而是直接检索多个网页、综合信息、生成一段带引用的自然语言答案。论文把这类系统统一称为生成式引擎(Generative Engine,GE)。
生成式引擎对用户和开发者都是好事——用户更快拿到答案,开发者获得更高的用户粘性和商业价值。但有一个群体被晾在了一边:网站和内容创作者。传统搜索引擎好歹还会把用户导流到网站本身,生成式引擎直接在答案里把内容”消化”完了,用户可能根本不需要点开原始链接,网站的曝光和流量因此被削弱。更麻烦的是,生成式引擎是黑箱、且产品迭代极快,创作者完全不知道自己的内容是如何被检索、摘要、引用的,也没有任何工具帮他们提升曝光。
作者由此提出了生成式引擎优化(Generative Engine Optimization, GEO)——某种意义上是”SEO 的下一代”——第一个面向内容创作者、专门针对生成式引擎可见度的优化框架。为了能够严谨评测各种优化手段,他们还构建了一个万级规模的查询基准 GEO-bench。实验显示,合适的优化手段能让一段内容在生成式引擎答案里的可见度提升最多达到 40%,并且这种提升在真实产品 Perplexity.ai 上同样能复现(最高 37%)。
生成式引擎到底是怎么运作的
论文先给生成式引擎做了一个形式化定义。一个生成式引擎接收用户查询 $q_u$(以及可选的个性化信息 $P_U$),输出一段自然语言回答 $r$:
$$f_{GE} := (q_u, P_U) \rightarrow r$$
它内部由两部分组成:
- 一组生成模型 $G={G_1, G_2, …, G_n}$,各自负责不同子任务,比如改写查询、生成摘要、撰写最终回答;
- 一个搜索引擎 $SE$,根据查询返回一组候选来源 $S={s_1, s_2, …, s_m}$。
论文中描述的典型工作流程(对应原文 Figure 2,与 BingChat 当时的设计接近)分为三步:
- 查询改写:一个改写模型 $G_{qr}$ 把用户原始问题拆解成若干个更适合检索的子查询;
- 检索与摘要:这些子查询被送进搜索引擎,取回一批排序后的来源网页,再由摘要模型 $G_{sum}$ 给每个来源生成摘要;
- 生成回答:回答生成模型 $G_{resp}$ 综合所有摘要,产出一段连贯的回答,并在句子层面标注引用来源。
由于大模型存在幻觉问题,引用机制至关重要:理想情况下,回答里每一句话都该有支撑它的引用(高引用召回),同时每条引用都应该真的能支撑它所标注的那句话(高引用精确度)。论文重点研究的是这种”一问一答”的单轮生成式引擎,但也在附录里讨论了可以扩展到多轮对话场景的情形。
给”可见度”下一个新定义
SEO 的核心逻辑很简单:网页在搜索结果里的平均排名越靠前,曝光和流量就越大。但这个逻辑搬到生成式引擎里完全不成立——因为生成式引擎根本不会给你列一份排好序的链接清单,它是把多个来源的信息揉在一段文字里,引用可能出现在任意位置,篇幅有长有短,呈现方式也千差万别。
所以论文提出了一套专为生成式引擎设计的”曝光度(impression)“指标体系,设计时遵循三条原则:对创作者有实际意义、可解释、容易被普通创作者理解。具体包括:
1. 词数占比(Word Count):某个来源被引用的句子总词数,占整段回答总词数的比例。如果一句话同时被多个来源引用,词数就在这些来源间平分。直觉很朴素——一个来源被引用得越”长”,它在答案里的存在感就越强。
2. 位置加权词数(Position-Adjusted Word Count):在词数占比的基础上,给排在回答靠前位置的引用句子加权,权重随位置呈指数衰减。这是因为大量点击率研究表明,用户对搜索结果的关注度随排名呈幂律式下降——同样的逻辑被沿用到了生成式引擎回答的句子顺序上。
3. 主观印象指标(Subjective Impression):前两个指标都是”客观计数”,但曝光度还有很多没法靠数单词解决的维度,比如这条引用跟用户问题到底有多相关、它对整段回答的”贡献”有多大、内容是否独特、读者主观上会不会觉得这条引用”显眼”、用户点开它的可能性有多大、呈现的信息是否多样化等。论文用 G-Eval(一种基于 GPT 打分、目前公认效果较好的 LLM 自动评测方法)让模型针对七个子维度分别打分,再做归一化处理,使其与位置加权词数具有可比的均值和方差。
这套指标体系比”看排名”复杂得多,但也更贴近生成式引擎回答的真实结构——原文 Figure 3 用一个对比图直观展示了传统搜索结果页(线性排序列表)和生成式引擎回答(引用穿插在一段文字里、长短位置各异)之间的差异,正是这种差异催生了重新设计可见度指标的必要性。
九种可以落地的 GEO 优化策略
确定了”怎么衡量”,接下来是”怎么提升”。论文用大语言模型对网站原文做改写,提出并验证了 9 种策略,每种策略本质上是一个函数 $f: W \rightarrow W’$,把原始网页内容 $W$ 变成优化后的内容 $W’$:
| 策略 | 做法 |
|---|---|
| 权威化(Authoritative) | 把文风改得更具说服力、更权威 |
| 增加统计数据(Statistics Addition) | 尽量用量化数据替代定性描述 |
| 关键词堆叠(Keyword Stuffing) | 像传统 SEO 那样,塞入更多与查询相关的关键词 |
| 引用来源(Cite Sources) | 加入来自可信来源的引用 |
| 增加引言(Quotation Addition) | 加入权威人士/机构的直接引语 |
| 通俗化(Easy-to-Understand) | 简化语言,降低理解门槛 |
| 提升流畅度(Fluency Optimization) | 改善文本的行文流畅性 |
| 独特用词(Unique Words) | 增加不常见、独特的措辞 |
| 专业术语(Technical Terms) | 增加专业/技术性词汇 |
其中关键词堆叠、引用来源、增加引言这三种需要补充一定的新内容,其余六种只是在不引入额外信息量的前提下改善”呈现方式”。为了公平比较,每个查询都会随机挑一个候选来源网站,分别用九种策略各改写一遍,再观察曝光度的变化。
怎么做评测:GEO-bench
由于此前完全没有公开的、面向生成式引擎场景的查询数据集,作者自己攒了一个——GEO-bench,包含 1 万条查询,来自 9 个不同来源,按 8000/1000/1000 划分为训练/验证/测试集:
- MS MARCO、ORCAS-I、Natural Questions:来自 Bing/Google 的真实用户查询,是搜索引擎研究领域常用的”老三样”;
- AllSouls(牛津大学 All Souls 学院的论述题)、LIMA(需要推理与创作能力的高难度问题)、Davinci-Debate(辩论类问题)、Perplexity.ai Discover(平台热门趋势查询)、ELI5(要求”像给五岁小孩解释”一样简单作答的复杂问题)、GPT-4 生成查询(覆盖科学、历史等多领域,兼顾导航型/交易型等不同查询意图)。
整体上,查询分布尽量贴近真实场景:80% 是信息型查询,交易型和导航型各占 10%。每条查询都配有 Google 搜索返回的前 5 个来源网页的清洗后文本。此外,作者用 GPT-4 给每条查询打上 7 类标签(难度、查询性质、领域、具体主题、敏感性、用户意图、答案类型),并人工核验了标注的精确率和召回率。最终,GEO-bench 覆盖 25 个领域(艺术、健康、游戏等)、9 种数据来源、7 种分类维度,是目前规模和多样性都相当可观的生成式引擎专用基准。
实验中使用的生成式引擎”原型”沿用了此前研究(Liu et al., 2023)的两步法设计:第一步用 Google 检索 Top-5 来源,第二步用 gpt-3.5-turbo 按统一的提示词模板(原文附录给出了完整 prompt,核心要求是”仅依据给定搜索结果作答,且每句话后面都要紧跟内联引用”)生成回答。为降低随机性,每条查询在温度 0.7 下采样 5 次取平均。
核心结果:哪些策略真正有效
下表是论文的主表(对应原文 Table 1),展示了 9 种策略在两大类指标上相对于”不做任何优化”基线的绝对得分(数值已归一化,使所有引用的曝光度加总为 1,再乘以常数方便阅读;具体数值越大代表曝光度越高):
| 方法 | 位置加权词数(总分) | 主观印象(均值) |
|---|---|---|
| 不优化(基线) | 19.3 | 19.3 |
| 关键词堆叠 | 17.7 | 20.2 |
| 独特用词 | 20.5 | 20.4 |
| 通俗化 | 22.0 | 20.5 |
| 权威化 | 21.3 | 22.9 |
| 专业术语 | 22.7 | 21.4 |
| 提升流畅度 | 24.7 | 21.9 |
| 引用来源 | 24.6 | 21.9 |
| 增加引言 | 27.2 | 24.7 |
| 增加统计数据 | 25.2 | 23.7 |
几个明显的结论:
- 传统 SEO 的招数在这里基本失效。关键词堆叠不仅没有提升,在”位置加权词数”这一项上反而比不优化还低,说明生成式引擎背后的模型理解文本依赖的是语义而非关键词匹配,简单堆词容易被模型识别为低质内容。
- 效果最好的三种策略是”增加引言""增加统计数据""引用来源”,相对基线的提升幅度在 30%–40%(位置加权词数)以及 15%–30%(主观印象)之间。这三者的共同点是:都没有要求创作者去”包装”文风,而是让内容本身更具可信度和信息密度——补一条权威来源、补一句直接引语、补一个具体数字,投入成本很低,但回报相当可观。
- 有点意外的是,**单纯改善文风的”提升流畅度”和”通俗化”**也能带来 15%–30% 的提升,说明生成式引擎不仅在乎”说了什么”,也在乎”说得好不好”。
- 反倒是把文风改得更”权威、有说服力”(Authoritative)这一项,提升并不显著——论文认为这说明生成式引擎对纯粹语气上的说服力已经有一定的鲁棒性,创作者更应该把精力放在内容本身的可信度上,而不是话术包装。
进一步分析
不同领域适合不同策略
实战中,SEO 从来不是”一招通吃”,GEO 同样如此。论文按 GEO-bench 的标签做了细分(对应原文 Table 3),发现:
| 策略 | 最适用领域(按效果排序) |
|---|---|
| 权威化 | 辩论类问题 > 历史 > 科学 |
| 提升流畅度 | 商业 > 科学 > 健康 |
| 引用来源 | 陈述性问题 > 事实类 > 法律与政府 |
| 增加引言 | 人与社会 > 解释类问题 > 历史 |
| 增加统计数据 | 法律与政府 > 辩论 > 观点类问题 |
这些规律相当符合直觉:辩论性问题天然欢迎更有说服力的论述方式;事实性问题需要引用作为”可验证性”的背书;法律、政府这类强调数据和条文的领域,统计数字的说服力远超抽象描述;而涉及个人叙事或历史事件的内容,直接引语能增添真实感和厚度。这也呼应了论文反复强调的观点:创作者应该根据自己网站的内容领域,而不是盲目套用一种”万能策略”。
当所有人都用上 GEO,谁受益最大?
一个自然的疑问是:如果未来所有创作者都开始用 GEO,会不会大家相互抵消、白忙一场?作者做了一个实验——把同一条查询下所有候选来源同时优化,观察不同排名位置的网站各自获得的相对提升(对应原文 Table 2):
| 方法 | 排名第1 | 排名第2 | 排名第3 | 排名第4 | 排名第5 |
|---|---|---|---|---|---|
| 权威化 | -6.0% | +4.1% | -0.6% | +12.6% | +6.1% |
| 提升流畅度 | -2.0% | +5.2% | +3.6% | -4.4% | +2.2% |
| 引用来源 | -30.3% | +2.5% | +20.4% | +15.5% | +115.1% |
| 增加引言 | -22.9% | -7.0% | +3.5% | +25.1% | +99.7% |
| 增加统计数据 | -20.6% | -3.9% | +8.1% | +10.0% | +97.9% |
结果相当鲜明:排名越靠后的网站,从 GEO 中获益越大;排名第一的网站反而可能因此被”拉下来”——比如”引用来源”策略让原本排名第五的网站可见度暴涨 115%,而排名第一的网站平均下降了 30.3%。原因不难理解:传统搜索引擎排名很依赖反向链接数量、域名权重这类”马太效应”明显的因素,中小创作者很难和大机构拼这些资源积累;但生成式引擎是基于内容本身去理解和组织信息,内容质量(引用、数据、引语)能直接转化为曝光度,而不再受制于这些结构性壁垒。换句话说,GEO 有潜力成为缩小大网站和小创作者之间数字鸿沟的工具——这对个体经营者、独立内容创作者是一个相当正面的信号。
策略组合起来效果更好
现实中创作者不会只用一招,论文挑出表现最好的四种策略(引用来源、提升流畅度、增加统计数据、增加引言),两两组合后测试效果(对应原文 Figure 4 的热力图)。结果显示,“提升流畅度”叠加”增加统计数据”是最佳组合,比单独使用任何一种策略都高出 5.5% 以上。更有意思的是,“引用来源”单独使用时效果排在四者中最末位(比增加引言低约 8%),但只要跟其他策略搭配使用,平均提升能达到 31.4%,是四种策略中”组合增益”最明显的一个——这提示创作者:有些策略的价值要在组合里才能完全释放,不能光看单独使用时的表现就否定它。
下表还原了这组两两组合的提升幅度(数据来自原文 Figure 4 的热力图,行列交叉处为两种策略叠加后相对基线的平均提升):
| 流畅度 | 统计数据 | 引用来源 | 增加引言 | 行均值 | |
|---|---|---|---|---|---|
| 流畅度 | 22.4% | 35.8% | 34.4% | 33.0% | 31.4% |
| 统计数据 | 35.8% | 27.0% | 30.3% | 35.4% | 32.1% |
| 引用来源 | 34.4% | 30.3% | 19.1% | 20.1% | 26.0% |
| 增加引言 | 33.0% | 35.4% | 20.1% | 30.3% | 29.7% |
对角线上的数值(比如”流畅度+流畅度”22.4%)代表同一策略重复使用两次,作为对照基准;非对角线则是两种不同策略叠加的效果。“行均值”一列正对应原文热力图最右侧那一列——它清楚地显示出”引用来源”单独使用时排名最末,但只要和别的策略搭配,平均提升反而能冲到第三高。
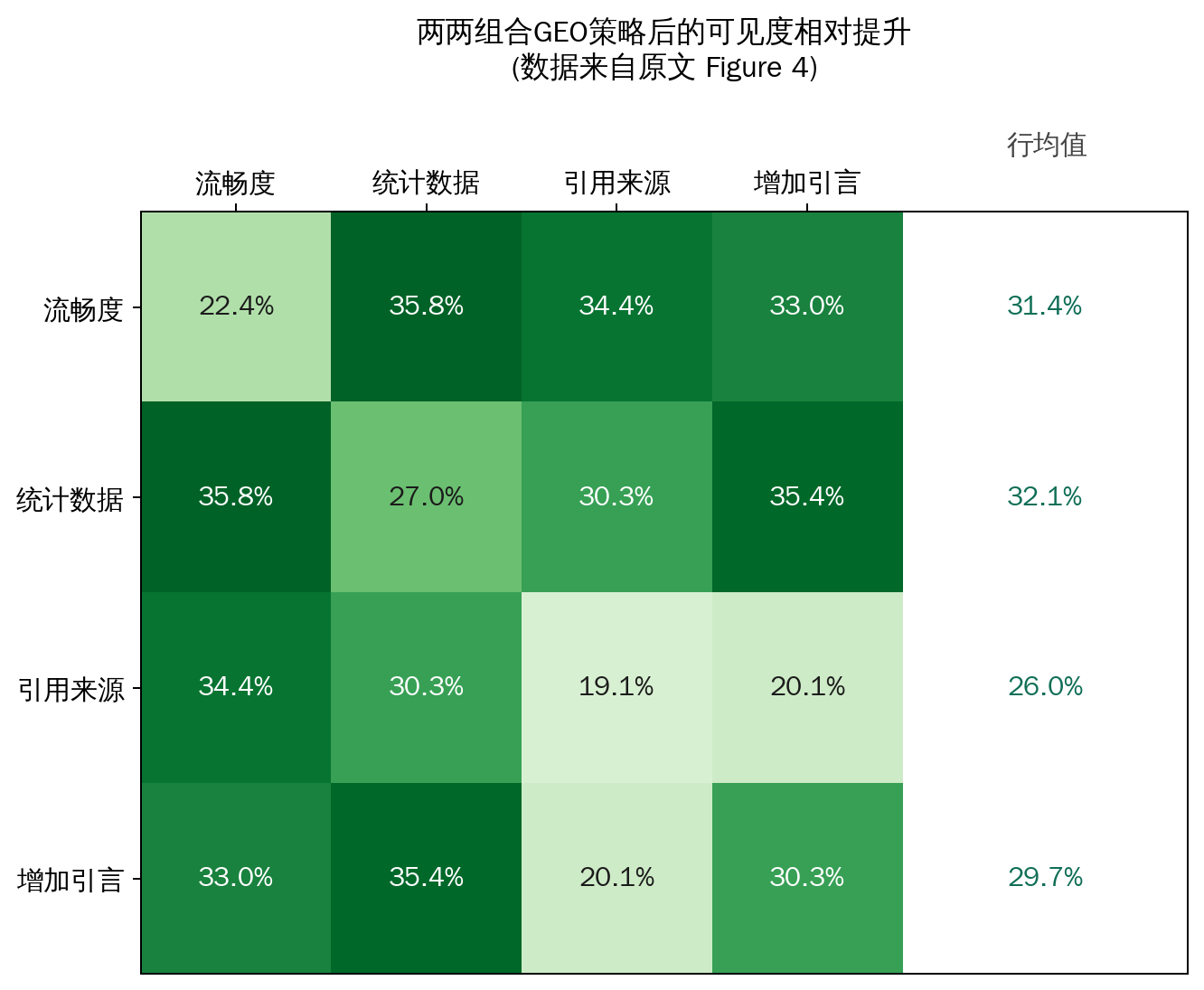
上图根据原文 Figure 4 的数据重新绘制,颜色越深代表组合后的提升幅度越大。
真实案例长什么样
论文给了几个直观的优化案例(对应原文 Table 4),三个例子分别对应”引用来源""增加统计数据""权威化”三种策略,共同特点是:改动幅度都很小,但带来的可见度提升非常可观——比如仅仅给一句关于瑞士人均巧克力消费量的陈述补上一个调研机构的来源标注,可见度就提升了 132.4%;给一句关于机器人取代人力的论述补充一个具体的增长百分比,提升了 65.5%;把一句关于某支球队战绩的平铺直叙改写得更斩钉截铁、更强调既有成就,提升了 89.1%。这些例子说明,GEO 优化往往不需要创作新内容,只需要给已有内容”补一个来源、补一个数字、调整一下语气的笃定程度”,门槛对普通创作者而言相当低。
走出实验室:在 Perplexity.ai 上的真实验证
为了证明这些发现不是”实验室里的自说自话”,作者把同样的方法搬到了真实上线、拥有大量用户的生成式引擎产品 Perplexity.ai 上做验证(由于 Perplexity.ai 不支持直接指定来源 URL,实验改为以文件上传的方式提供源文本,并限定回答只能基于上传文件生成),抽样测试 200 条查询(对应原文 Table 5):
| 方法 | 位置加权词数 | 主观印象 |
|---|---|---|
| 不优化(基线) | 24.1 | 24.7 |
| 关键词堆叠 | 21.9 | 28.1 |
| 增加引言 | 29.1 | 32.1 |
| 增加统计数据 | 26.2 | 33.9 |
结果和实验室设置高度一致:关键词堆叠在位置加权词数上依然是负向的(比基线还低约 10%),而增加引言、增加统计数据这类”内容增信”型策略依旧表现突出,分别带来约 22% 和 37% 的提升。这一结果有三层意义:一是再次确认了”为生成式引擎专门设计优化方法”的必要性;二是证明了这些方法不依赖某个特定的实验性生成式引擎,具备跨产品的泛化能力;三是说明创作者完全可以直接照搬这些简单易行的策略,在真实产品上获得实际收益。
这项研究放在更大的脉络里
论文把自己的工作和三类前序研究做了区分:
- 带证据的答案生成:像 WebGPT 这样训练模型在网页环境中导航并生成有来源支撑的答案,以及其他基于搜索结果生成回答的方法,GEO 的工作是在这些系统之上,提供一个统一的评测基准,并且——与近期一篇探讨”如何用对抗性文本操纵 LLM 推荐以提升商品曝光”的工作不同——GEO 提出的是非对抗性的、面向任意网站内容的优化策略。
- 检索增强生成:RAG、REALM 等工作主要解决语言模型”记不住知识”的问题,而生成式引擎的任务范围更广,既要生成答案又要全程标注来源,并且涵盖查询改写、来源筛选等一整套子任务,不只是单纯的检索。
- 传统 SEO:近 25 年的 SEO 研究分为站内优化(改善内容和体验)和站外优化(建立反向链接、提升域名权威度)两条线,但这套逻辑建立在”搜索引擎做关键词匹配”的假设上,在生成式引擎这种由生成模型驱动、不局限于关键词匹配的环境里基本不适用,这正是 GEO 存在的意义。
结语与局限
总结下来,这篇论文做了三件事:形式化定义了生成式引擎,提出了第一套面向生成式引擎的创作者优化框架 GEO(包括可见度指标体系和 9 种具体优化策略),以及构建并开源了评测基准 GEO-bench。核心发现是:补充引用、引语和统计数据这类”增信型”内容改动,能让网站在生成式引擎回答中的可见度提升最高达 40%;不同领域适合不同策略;多种策略组合使用通常优于单独使用;而且排名靠后的小网站从 GEO 中获益尤其明显,这对个体创作者和中小网站是一个积极信号。
作者也坦诚地列出了几点局限:首先,生成式引擎本身在快速演变,正如 SEO 历史上经历过的那样,GEO 方法很可能也需要随之持续迭代;其次,尽管 GEO-bench 力求贴近真实查询分布,但查询的性质会随时间变化,基准需要持续更新;第三,由于搜索引擎排序算法本身是黑箱,论文没有评估 GEO 修改是否会反过来影响传统搜索排名——作者的判断是,GEO 所做的改动主要集中在文本内容层面,并不触及域名、反向链接等传统排名因子,因此影响应该有限;最后,随着模型上下文长度的提升,未来生成式引擎能够”消化”的来源数量会更多,这也可能进一步降低”搜索排名位置”本身的重要性。整体来看,这篇论文更像是给一个全新领域打地基——它提出的框架、指标和基准,是为了让后续研究者能在一个共同的标准上继续往前推进。